LMM: When Large Language Models Learn to Remember
LLM as memory for LLM

An Analogy
After spending months working with Claude Code on long-running projects, I arrived at an analogy that I can’t unsee: Large Language Models are CPUs with fixed-size registers, not complete form general-purpose computers.
The context window — whether it’s 128K, 200K, or 1M tokens — is not “memory” in any meaningful architectural sense. It’s a register file. It’s fast, all actual computation happens inside it, but it is in fact finite and temporary. You can make registers bigger (and the industry is), but the nature of the constraint doesn’t change. The moment you accept this framing, a cascade of implications follows.
What We Have: A CPU Without an Operating System
Current LLM tooling is beginning to resemble the early layers of a computer architecture, but critical components are still missing.
The instruction set is taking shape. Tool Use, Function Calling, Skills, and System Prompts act as something like a default instruction set for the CPU. When Claude Code scans a project, reads a SKILL.md file, or follows an AGENTS.md protocol, it’s executing pre-defined instruction patterns. This is real — and it works surprisingly well.
But between the CPU and real work, we’re missing almost everything. In a von Neumann architecture, the CPU doesn’t hold the entire program state in registers. There’s a memory hierarchy — L1 cache, L2 cache, RAM, disk — and an operating system that orchestrates the flow of data between these layers. Current LLM systems have almost none of this. What they have instead is:
A context window (registers) that resets between sessions or even within a session
Flat files like
memory.mdor.cursorrules(something between a rudimentary disk and a crib sheet taped to the monitor)Brute-force re-scanning of entire codebases when context is lost (the equivalent of reading the entire hard drive into registers every time you need one variable)
This is like running a 1950s computer where the operator manually loads punch cards for every single operation. It works, but it doesn’t scale.
The Missing Key Components
To go from “CPU with tools” to something resembling an operating system, LLMs need three capabilities that don’t yet exist in any systematic form:
1. Addressing: What Do I Need Right Now?
When a user types a prompt, the system needs to figure out what existing knowledge is relevant — without loading everything. Today’s approach is either “stuff everything into the context and pray that Attention is All You Need magic kicks in” or “re-scan the codebase from scratch.” Neither is tenable.
What we need is a form of semantic addressing: given the current task, what stored information has the highest relevance? This isn’t just vector similarity search over a knowledge base (though that’s a start). It’s more like the CPU’s memory management unit — a mechanism that translates “what I need” into “where to find it” and loads just enough into the context window to proceed.
The hard part: relevance isn’t static. The same piece of stored knowledge might be critical for one task and noise for another. The addressing mechanism needs to be dynamic, context-sensitive, and fast.
2. Storage That Evolves: Beyond Markdown Files
Here’s where it gets interesting. The “memory” that LLM tools currently use — files like memory.md, accumulated conversation logs, project documentation — is dead storage. It’s a pile of text that grows nearly monotonically and never reorganizes itself in any scalable way (even though we can manually or prompt an LLM to modify parts of it).
Real memory doesn’t work this way. Real memory compresses, abstracts, and restructures. When you’ve worked on a codebase for six months, you don’t remember every commit message. You remember patterns: “this module is fragile,” “that API has an awkward auth flow,” “the team prefers composition over inheritance here.” These aren’t stored as literal strings. They’re distilled motifs that can be regenerated on demand into whatever level of detail the current task requires.
What LLM systems need isn’t better filing cabinets. They need storage that continuously refines itself — merging redundant information, elevating recurring patterns, deprecating stale knowledge, and maintaining a compressed representation that can be unpacked and generated into relevant context when needed.
3. On-Demand Generation: Memory as Reconstruction
This leads to an insight that may sound cliché but is nonetheless profound: memory is not retrieval — memory is generation.
When you “remember” how a complex system works, you’re not playing back a recording. You’re reconstructing — generating a fresh explanation from compressed representations, guided by the current question. This is why the same memory produces different outputs depending on context — you explain the same system differently to a junior developer than to an architect.
For LLMs, this means the ideal memory system doesn’t store and retrieve documents. It stores compressed representations and generates the right context on demand, tailored to the current task. The context window (registers) gets filled not with pre-written text, but with freshly generated, task-relevant information derived from accumulated experience.
A Radical Idea: LLM as Memory for LLM
This line of thinking leads somewhere unexpected: what if the memory itself is a language model?
Think about it. We need a system that:
Ingests streams of information continuously
Compresses that information into useful representations
Can generate relevant context on demand based on a query
Improves its representations over time
That’s... a language model. Specifically, a specialized language model whose job isn’t to be a general-purpose assistant, but to serve as the memory substrate for a larger working model.
I’m calling this a Large Memory Model (LMM).
How LMM Would Work
The architecture would look something like this:
The Working Model (the “CPU”) is your standard large language model — Claude, GPT, or whatever comes next. It handles the current task, reasons about the prompt, and produces outputs. Its context window is the register file. Its core capabilities come from world knowledge acquired through compressing vast data, and reasoning abilities derived from reinforcement learning on top of that.
The Memory Model (the LMM) is a smaller, privately deployable, continuously updated model that serves as the memory hierarchy. It:
Ingests every interaction, every code change, every document — the full stream of a user’s working context
Compresses this stream into its weights through continuous fine-tuning
Generates relevant context when queried by the working model — “given this task, what do I need to know?”
Evolves its representations as new information arrives, naturally deprecating stale knowledge
The critical innovation is that the LMM’s weights are continuously updated in a way that mirrors how biological memory works:
High-salience information (an important architectural decision, a critical bug fix, a key business requirement) significantly updates model weights — like how emotionally charged or highly relevant events create strong memories
Low-salience information (routine log output, boilerplate changes, passing observations) barely perturbs the weights — like how you don’t remember what you had for lunch on an ordinary Tuesday
Repeated patterns naturally reinforce themselves through multiple weight updates — like how procedural memory forms through repetition
The Gating Mechanism: A Subconscious for LLMs
This requires what I’d call a salience gate — a mechanism that determines how much each piece of incoming information should alter the memory model’s weights. This is analogous to the subconscious filtering that biological brains perform constantly:
Walking past a stranger on the subway: almost zero memory formation
Your colleague explaining a new API design: significant memory formation
A production incident at 3 AM: very strong memory formation
The salience gate would operate as a learned function — possibly another small model, or a component of the LMM itself — that evaluates incoming information against the current state of memory and determines the appropriate learning rate for that specific input.
This isn’t just a nice-to-have. It’s essential. Without salience gating, the memory model would either:
Update too aggressively and lose older knowledge (catastrophic forgetting)
Update too conservatively and fail to incorporate new information
Treat everything equally and drown signal in noise
A more intuitive way to grasp this dual-model architecture: the working LLM is the conscious mind — deliberate, focused, operating on what’s in the context window right now and its interaction with world knowledge. The LMM is the subconscious — vast, compressed, always available, surfacing what’s needed when it’s needed.
In a sense, memory has always been compression plus generation. When you remember something, you’re not reading a file — you’re running a generative model in your head, conditioned on compressed traces of past experience. LMM would make this literal.
Privacy: An Architectural Prerequisite for LMM
LMM deals with a user’s private information — your project decisions, the evolution of your code, your work habits, your communication patterns. This dictates a fundamental architectural constraint: LMM must be deployed in the user’s private environment.
Peter Steinberger, founder of OpenClaw, raised a pointed question in an interview: which would you be more reluctant to let others see — your Google search history, or your memory.md file? The question cuts to the heart of it. What LMM compresses isn’t public knowledge — it’s a user’s most intimate experience, exploration and memory, deeper and more structured than search history, a reflection of what someone is truly doing and thinking.
This means LMM cannot and should not be a mechanism improvement to some third-party general-purpose LLM. What users receive is the LMM’s architecture and algorithms — essentially a piece of software containing no proprietary information. As users continuously feed it input and interact with it, this initially empty model is gradually “filled” with their private information, becoming increasingly attuned to them. In the short term, it should perform at least as well as tools like Claude Code do within a single session in terms of understanding the user and their project. In the long term, it becomes a compression, storage, and generation tool for private memory — entirely independent of any external general-purpose LLM “CPU.”
Your memory belongs to you, not to any model provider.
Positioning and Distinctions
LMM ≠ RAG
It’s worth distinguishing this from Retrieval-Augmented Generation (RAG), the current industry standard for giving LLMs access to external knowledge:
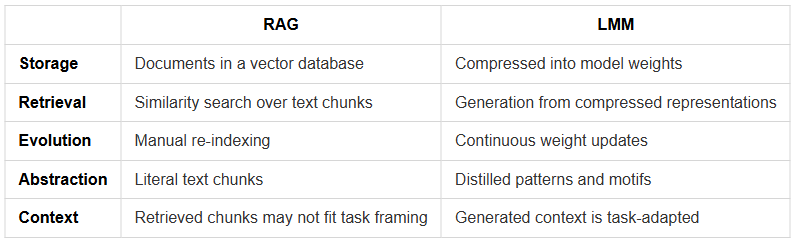
RAG gives you search. LMM gives you understanding. RAG retrieves what was written. LMM generates what you need to know.
LMM ≠ Model-Internal Memory Modules
There’s another class of work that needs to be distinguished: recent academia has made significant progress building memory mechanisms inside model architectures. Google’s Titans (2025) introduced a “neural long-term memory module” — a deep MLP network that continuously updates its weights during inference, using a gradient-based “surprise” metric to modulate the intensity of memory updates, paired with adaptive weight decay to manage memory capacity and forgetting. Stanford/NVIDIA’s TTT-E2E (2025) reframed long-context modeling as a continual learning problem, where the model compresses context into its weights via next-token prediction during inference, with meta-learning at training time to optimize initialization for this test-time adaptation. MemoryLLM (ICML 2024) embedded a fixed-size self-updatable memory pool within the transformer’s latent space. MEGa (2025) injected event memories into gated low-rank weights.
These are exciting developments, but they address a different problem: how to give a model architecture itself better long-range memory capabilities. They modify model internals — changing attention mechanisms, adding memory layers, adjusting weight update rules — so models can handle longer input sequences.
LMM addresses a different problem: when a user is continuously working with a powerful language model whose architecture they cannot modify, how do you accumulate, compress, and provide on demand that specific user’s private context?
This is the distinction between a model architecture problem and a systems architecture problem. LMM’s premise is that the working model is a black box — provided by Anthropic or OpenAI, constantly being upgraded, something the user cannot and should not modify internally. What you need is an external, user-side, persistent memory layer that exists independently of any specific working model. When Claude gets a new version, when GPT gets a new version, your memory doesn’t disappear.
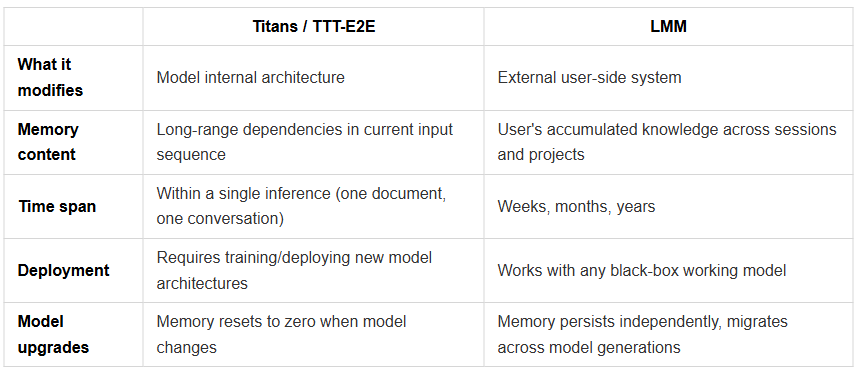
Titans makes models smarter at processing long documents. LMM gives users persistent, portable, personalized AI memory. The two are complementary, not competitive — an ideal system could very well use a Titans-architecture model as the working model while using LMM to provide user-side long-term memory.
Why Weight Space, Not Token Space?
There’s a question worth confronting directly: why compress user memory into model weights, rather than storing it as carefully managed text (token space), as current mainstream approaches do?
Letta (the MemGPT team) explicitly chose the opposite direction in 2025 — they argued that “weights are temporary; the learned context (tokens) is what persists,” pursuing continual learning in token space so agent memory can migrate across model generations. This is a reasonable engineering choice, especially given current infrastructure constraints.
But I believe that in the long run, weight-space memory has a fundamental advantage. The argument is simple:
If existing LLMs can compress billions of people’s decades of internet content and millennia of accumulated text into model weights, then the same mechanism can certainly compress one person’s information interactions across a few decades of their life. Personal memory is a subset of humanity’s collective knowledge — orders of magnitude smaller in scale. The success of LLMs has already proven at the trillion-token scale that the “compress into weights, generate on demand” paradigm works. Nobody would argue that “storing internet content as markdown files and retrieving them” is better than “training a language model.” By the same logic, when a person’s accumulated information is large enough and spans a long enough time horizon, weight compression should be more efficient than ever-expanding text memory files.
The fundamental limitation of token-space memory is that it’s always literal. No matter how much you refine it, it stores text and retrieves text. Weight-space memory stores patterns — statistical regularities distilled from vast information. When you ask an LMM that has been “trained” on a codebase, “what should I watch out for with this project’s auth module?” — it isn’t searching for something you once wrote. It’s generating an answer tailored to your current question from compressed understanding, just as ChatGPT doesn’t search for a specific web page but generates answers from its compressed world knowledge.
This also yields an elegant symmetry: LLM is to humanity’s collective knowledge as LMM is to an individual’s private knowledge. The former is already a multi-hundred-billion-dollar industry. The latter — for a specific person doing a specific job — may be equally important.
What Exists Today (and What’s Still Missing)
The seeds of this architecture are already visible:
Claude Code scans project structures, reads documentation files, and uses that context to inform its work. But it does this from scratch every time, with no persistent model of the project.
Memory systems (like Claude’s memory, ChatGPT’s memory, or community tools like OpenClaw’s memory.md) accumulate facts as text. But they’re flat, non-evolving, and don’t compress or abstract.
Fine-tuning updates model weights with new data. But it’s a batch process — you can’t fine-tune a model continuously in real-time as a user works.
The gap between what exists and the LMM vision is primarily an infrastructure problem:
Real-time weight updates: We need the ability to update a model’s weights incrementally, with varying learning rates, without catastrophic forgetting. This is a hard but tractable ML problem.
Salience estimation: We need a mechanism to determine how much each piece of information matters. This could itself be a learned function.
Query interface: The working model needs a way to “ask” the memory model for relevant context, and the memory model needs to generate it in a format the working model can use in its context window.
Graceful degradation: When the memory model doesn’t have relevant information, it should say so rather than hallucinate context (though, to be fair, human memory hasn’t fully solved this problem either).
Where This Goes
If this architecture works, the implications are significant:
For developers: Claude Code (or its successors) wouldn’t just scan your repo — it would deeply and continuously understand your repo, the way a senior engineer knows a codebase they’ve worked on for years, rather than through manually editing or prompting an LLM to update CLAUDE.md and memory.md files — an approach that fundamentally doesn’t scale.
For knowledge work: Your AI assistant wouldn’t need to be re-briefed every session. It would carry genuine institutional knowledge, accumulated over months of collaboration.
For the industry: The race might shift from “biggest context window” to “best memory architecture.” A model with 200K context but brilliant memory could outperform one with 2M context but no memory — just as a modern CPU with a good cache hierarchy outperforms one that tries to put everything in registers.
The next breakthrough in LLMs might not be about making the CPU faster or the registers bigger. It might be about finally giving them a real memory system.